video
Deep Learning Course - Level: Advanced


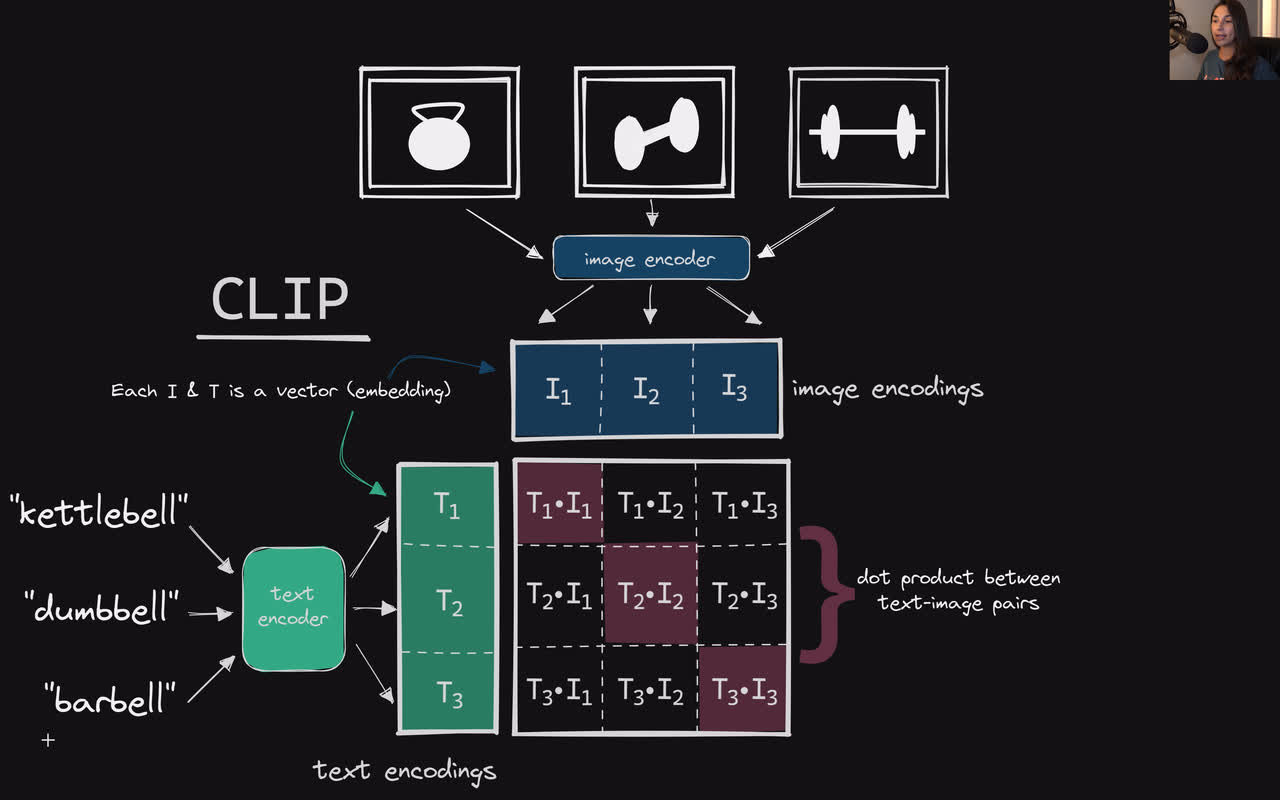
Now we understand how a diffusion model generates images based on what it learned by denoising noisy images from the training set.
As we previously mentioned, in addition to passing a noisy image to a diffusion model as input, we also pass in text describing what it is that we want an image of. This text "guides" the model towards generating the type of image we want and is referred to as conditional generation, as we are conditioning the model to generate images based on the text input.
Committed by on
 DEEPLIZARD
Message
DEEPLIZARD
Message