video
Deep Learning Course - Level: Advanced


Now we know how the text portion of input is processed before being passed to U-Net during training and inference. Let's now explore how the image portion of input is processed.
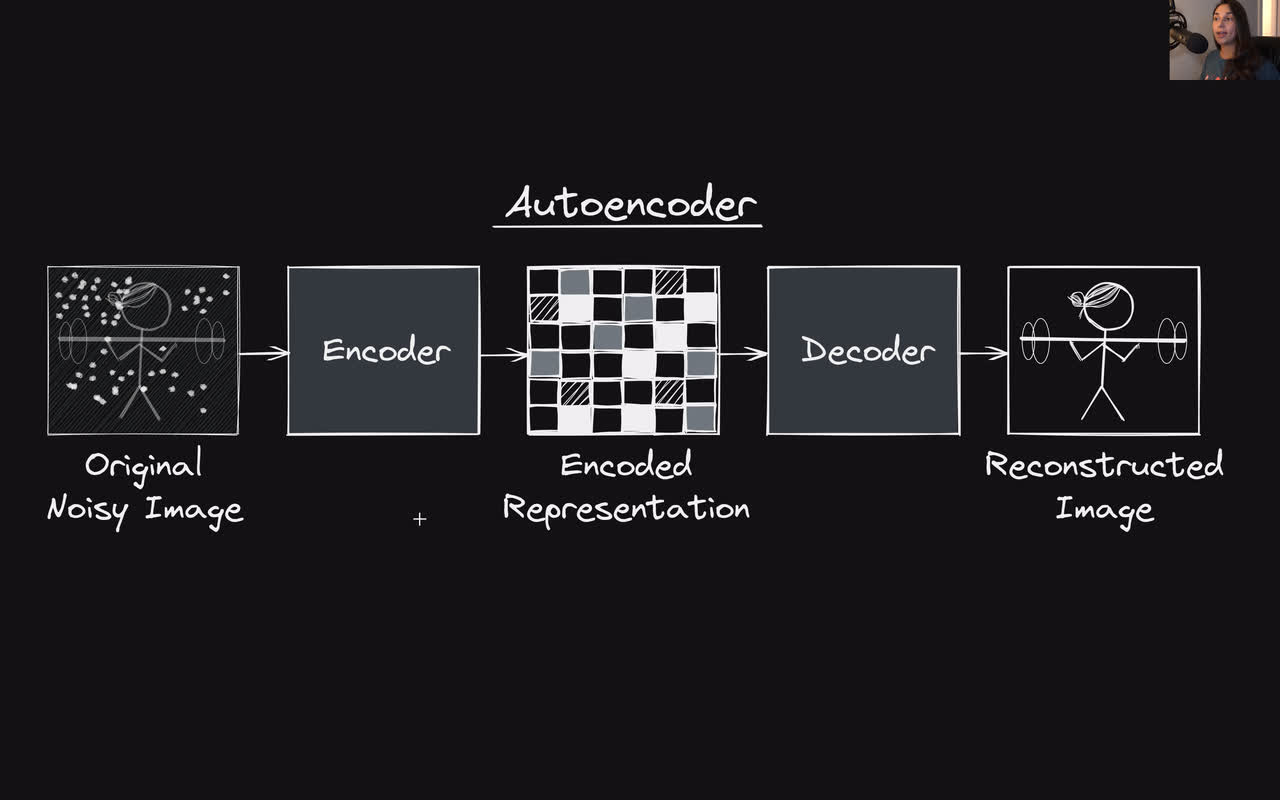
Before passing the input image to U-Net, we first pass it to a pre-trained variational autoencoder to compress the image into a latent.
Committed by on
 DEEPLIZARD
Message
DEEPLIZARD
Message