

Zero Padding in Convolutional Neural Networks explained
text
Zero Padding in Convolutional Neural Networks
What's going on everyone? In this post, we're going to discuss zero padding as it pertains to convolutional neural networks. What the heck is this mysterious concept? We're about to find out, so let's get to it.

We're going to start out by explaining the motivation for zero padding, and then we'll get into the details about what zero padding actually is. We'll then talk about the types of issues we may run into if we don't use zero padding, and then we'll see how we can implement zero padding in code using Keras.
We're going to be building on some of the ideas that we discussed in our post on convolutional neural networks, so if you haven't seen that yet, go ahead and check it out, and then come back to to this one once you've finished up there.
Convolutions reduce channel dimensions
We've seen in our post on CNNs that each convolutional layer has some number of filters that we define, and we also define the dimension of these filters as well. We also showed how these filters convolve image input.
When a filter convolves a given input channel, it gives us an output channel. This output channel is a matrix of pixels with the values that were computed during the convolutions that occurred on the input channel.
When this happens, the dimensions of our image are reduced.
Image dimensions are reduced.
Let's check this out using the same image of a seven that we used in our previous post on CNNs. Recall, we have a 28 x 28 matrix of the pixel values from an image of a
7 from the MNIST data set. We'll use a 3 x 3 filter. This gives us the following the items:
A 28 x 28 single input channel (grayscale image):
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.4 | 0.4 | 0.3 | 0.5 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.4 | 0.5 | 0.9 | 0.9 | 0.9 | 0.9 | 0.9 | 0.9 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.9 | 0.7 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.5 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.7 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.9 | 1.0 | 0.8 | 0.8 | 0.8 | 0.8 | 0.8 | 0.5 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 0.5 | 0.9 | 1.0 | 1.0 | 0.7 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.1 | 0.3 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.1 | 0.8 | 1.0 | 1.0 | 0.5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.3 | 1.0 | 1.0 | 0.9 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.3 | 1.0 | 1.0 | 0.9 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.4 | 0.6 | 1.0 | 1.0 | 1.0 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.1 | 0.5 | 0.9 | 0.9 | 0.9 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.9 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.3 | 0.5 | 0.9 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.6 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.1 | 0.7 | 1.0 | 1.0 | 1.0 | 1.0 | 0.9 | 0.8 | 0.8 | 0.3 | 0.3 | 0.8 | 1.0 | 1.0 | 0.5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.4 | 0.9 | 1.0 | 0.9 | 0.9 | 0.5 | 0.3 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.8 | 1.0 | 0.9 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.7 | 1.0 | 0.7 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.2 | 0.9 | 1.0 | 0.9 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.1 | 0.5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.3 | 1.0 | 1.0 | 0.7 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.5 | 1.0 | 0.9 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.8 | 1.0 | 1.0 | 0.7 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.9 | 1.0 | 0.9 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.3 | 1.0 | 0.9 | 0.3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.8 | 1.0 | 0.6 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.5 | 0.3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
A 3 x 3 filter:
A 26 x 26 output channel:
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.3 | 0.4 | 0.6 | 0.7 | 0.5 | 0.4 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.3 | 0.6 | 1.2 | 1.4 | 1.6 | 1.6 | 1.6 | 1.6 | 1.9 | 1.9 | 2.2 | 2.3 | 2.1 | 2.0 | 1.7 | 0.9 | 0.5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.5 | 1.2 | 1.8 | 2.6 | 2.7 | 3.0 | 3.0 | 3.0 | 3.0 | 3.4 | 3.5 | 3.8 | 4.0 | 3.7 | 3.6 | 3.2 | 2.3 | 1.5 | 0.5 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1.1 | 2.1 | 3.2 | 4.2 | 4.4 | 4.7 | 4.7 | 4.5 | 4.2 | 4.0 | 3.8 | 3.9 | 3.9 | 4.1 | 4.5 | 4.7 | 4.1 | 3.1 | 1.5 | 0.5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1.1 | 2.0 | 3.1 | 3.6 | 3.3 | 3.2 | 3.2 | 3.1 | 2.9 | 2.7 | 2.5 | 2.5 | 2.5 | 2.7 | 3.0 | 3.9 | 4.4 | 4.1 | 2.9 | 1.4 | 0.3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.9 | 1.4 | 2.1 | 2.2 | 1.8 | 1.7 | 1.7 | 1.5 | 1.1 | 0.8 | 0.5 | 0.5 | 0.5 | 0.8 | 1.3 | 2.4 | 3.7 | 4.5 | 4.0 | 2.4 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.1 | 0.3 | 0.3 | 0.3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.1 | 1.3 | 2.8 | 4.2 | 4.7 | 2.8 | 1.6 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.4 | 1.2 | 2.9 | 3.9 | 5.1 | 3.1 | 2.2 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.1 | 0.4 | 1.0 | 1.3 | 1.6 | 1.9 | 2.4 | 3.7 | 4.4 | 5.2 | 3.8 | 2.5 | 0.7 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.2 | 0.5 | 1.1 | 1.7 | 2.3 | 2.7 | 3.0 | 3.4 | 3.7 | 4.6 | 4.9 | 5.2 | 4.1 | 2.5 | 1.2 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.1 | 0.7 | 1.3 | 1.9 | 2.6 | 3.2 | 4.0 | 4.4 | 4.8 | 4.4 | 4.2 | 4.5 | 4.8 | 5.2 | 4.5 | 2.7 | 1.6 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.4 | 1.0 | 1.8 | 2.6 | 3.3 | 3.8 | 3.9 | 3.8 | 3.6 | 3.4 | 3.0 | 2.9 | 3.6 | 4.1 | 5.0 | 3.8 | 2.5 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.8 | 1.7 | 3.0 | 3.5 | 3.7 | 3.3 | 3.0 | 2.5 | 2.2 | 1.9 | 1.3 | 1.3 | 2.4 | 3.3 | 4.8 | 3.4 | 2.3 | 0.6 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.9 | 2.0 | 2.7 | 3.2 | 2.6 | 1.8 | 1.3 | 0.7 | 0.4 | 0.1 | 0.0 | 0.4 | 2.2 | 3.3 | 4.6 | 3.0 | 2.0 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.7 | 1.4 | 1.6 | 1.7 | 0.7 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.8 | 2.5 | 3.7 | 4.2 | 2.6 | 1.5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.1 | 0.5 | 0.2 | 0.5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.7 | 1.7 | 3.3 | 4.0 | 3.6 | 2.2 | 0.8 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.3 | 2.3 | 4.0 | 3.9 | 2.8 | 1.6 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.3 | 2.3 | 3.1 | 4.5 | 3.4 | 2.0 | 0.8 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.9 | 2.6 | 3.4 | 3.8 | 2.5 | 1.2 | 0.2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.2 | 2.0 | 2.8 | 2.4 | 1.5 | 0.3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.3 | 2.0 | 1.3 | 0.6 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
We can see that the output is actually not the same size as the original input. The output size is 26 x 26. Our original input channel was 28 x 28, and now we have an output
channel
that has shrank in size to 26 x 26 after convolving the image. Why is that?
With our 28 x 28 image, our 3 x 3 filter can only fit into 26 x 26 possible positions, not all 28 x 28. Given this, we get the resulting
26 x 26 output. This is due to what happens when we convolve the edges of our image.
For ease of visualizing this, let's look at a smaller scale example. Here we have an input of size 4 x 4 and then a 3 x 3 filter. Let's look at how many times we
can
convolve our input with this filter, and what the resulting output size will be.
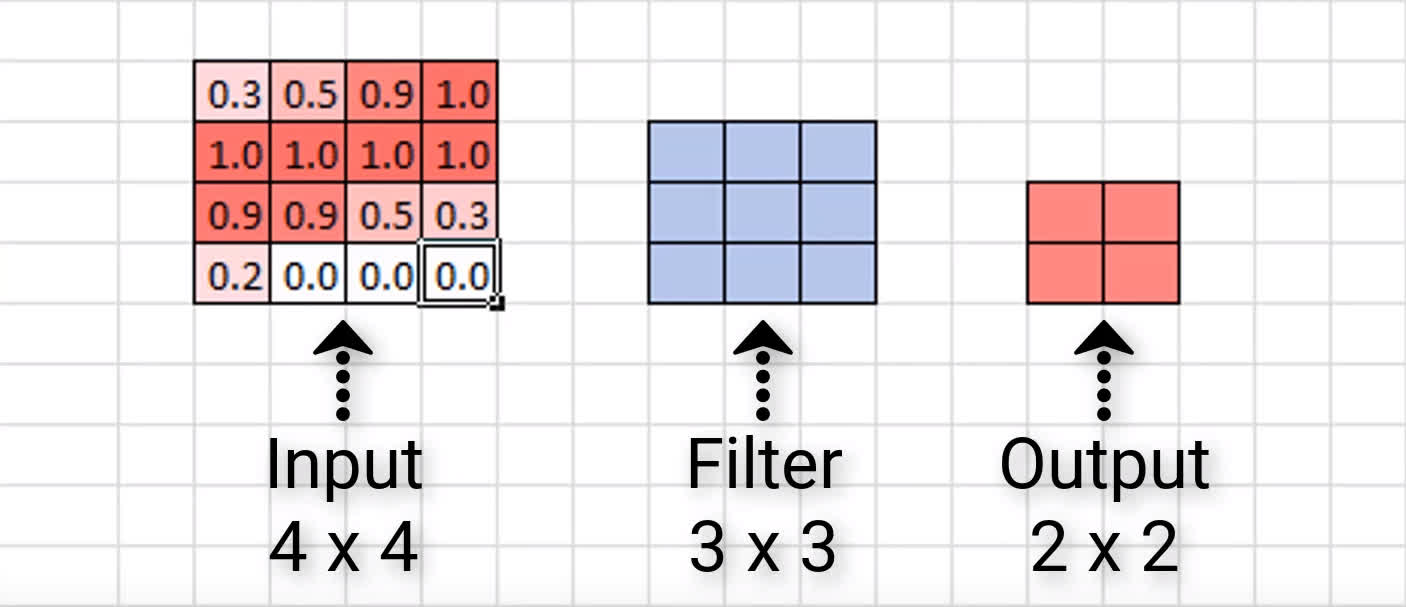
This means that when this 3 x 3 filter finishes convolving this 4 x 4 input, it will give us an output of size 2 x 2.
We see that the resulting output is 2 x 2, while our input was 4 x 4, and so again, just like in our larger example with the image of a seven, we see that our output is indeed
smaller
than our input in terms of dimensions.
We can know ahead of time by how much our dimensions are going to shrink. In general, if our image is of size n x n, and we convolve it with an f x f filter, then the size of
the
resulting output is \((n – f + 1)\) x \((n – f + 1)\).
Let's see if this holds up with our example here.
Our input was size 4 x 4, so 4 would be our n, and our filter was 3 x 3, so 3 would be our f. Substituting these values in
our
formula, we have:
$$(n - f + 1) = (4 - 3) + 1 = 2$$
Indeed, this gives us a 2 x 2 output channel, which is exactly what we saw a moment ago. This holds up for the example with the larger input of the seven as well, so check that for yourself
to confirm that the formula does indeed give us the same result of an output of size 26 x 26 that we saw when we visually inspected it.
Issues with reducing the dimensions
Consider the resulting output of the image of a seven again. It doesn't really appear to be a big deal that this output is a little smaller than the input, right?
We didn't lose that much data or anything because most of the important pieces of this input are kind of situated in the middle. But we can imagine that this would be a bigger deal if we did have meaningful data around the edges of the image.
Additionally, we only convolved this image with one filter. What happens as this original input passes through the network and gets convolved by more filters as it moves deeper and deeper?
Well, what's going to happen is that the resulting output is going to continue to become smaller and smaller. This is a problem.
If we start out with a 4 x 4 image, for example, then just after a convolutional layer or two, the resulting output may become almost meaningless with how small it becomes. Another issue is
that we're losing valuable data by completely throwing away the information around the edges of the input.
What can we do here? Queue the super hero music because this is where zero padding comes into play.
Zero padding to the rescue
Zero padding is a technique that allows us to preserve the original input size. This is something that we specify on a per-convolutional layer basis. With each convolutional layer, just as we define how many filters to have and the size of the filters, we can also specify whether or not to use padding.
What is zero padding?
We now know what issues zero padding combats against, but what actually is it?
Zero padding occurs when we add a border of pixels all with value zero around the edges of the input images. This adds kind of a padding of zeros around the outside of the image, hence the name zero padding. Going back to our small example from earlier, if we pad our input with a border of zero valued pixels, let's see what the resulting output size will be after convolving our input.
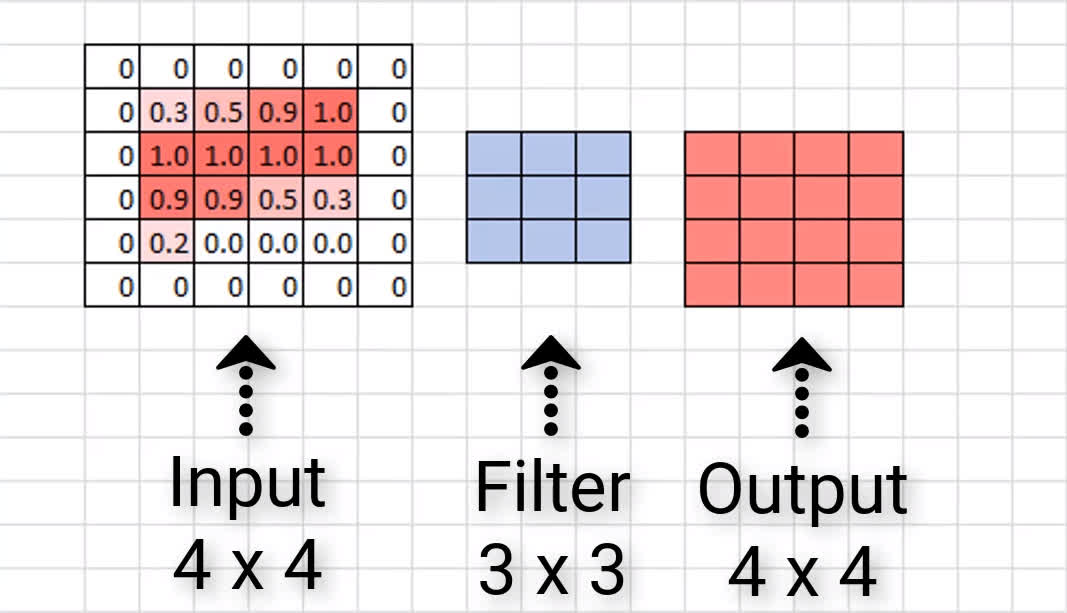
We see that our output size is indeed 4 x 4, maintaining the original input size. Now, sometimes we may need to add more than a border that's only a single pixel thick. Sometimes we
may
need to add something like a double border or triple border of zeros to maintain the original size of the input. This is just going to depend on the size of the input and the size of the filters.
The good thing is that most neural network APIs figure the size of the border out for us. All we have to do is just specify whether or not we actually want to use padding in our convolutional layers.
Valid and same padding
There are two categories of padding. One is referred to by the name valid. This just means no padding. If we specify valid padding, that means our convolutional layer is not going to pad at all, and our input size won't be maintained.
The other type of padding is called same. This means that we want to pad the original input before we convolve it so that the output size is the same size as the input size.
| Padding Type | Description | Impact |
|---|---|---|
| Valid | No padding | Dimensions reduce |
| Same | Zeros around the edges | Dimensions stay the same |
Now, let's jump over to Keras and see how this is done in code.
Working with code in Keras
We'll start with some imports:import keras
from keras.models import Sequential
from keras.layers import Activation
from keras.layers.core import Dense, Flatten
from keras.layers.convolutional import *
Now, we'll create a completely arbitrary CNN.
model_valid = Sequential([
Dense(16, input_shape=(20,20,3), activation='relu'),
Conv2D(32, kernel_size=(3,3), activation='relu', padding='valid'),
Conv2D(64, kernel_size=(5,5), activation='relu', padding='valid'),
Conv2D(128, kernel_size=(7,7), activation='relu', padding='valid'),
Flatten(),
Dense(2, activation='softmax')
])
It has a dense layer, then 3 convolutional layers followed by a dense output layer.
We've specified that the input size of the images that are coming into this CNN is 20 x 20, and our first convolutional layer has a filter size of 3 x 3, which is
specified
in Keras with the
kernel_size parameter. Then, the second conv layer specifies size 5 x 5, and the third, 7 x 7.
With this model, we're specifying the parameter called padding for each convolutional layer. We're setting this parameter equal to the string
'valid'. Remember from earlier that, valid padding means no padding.
This is actually the default for convolutional layers in Keras, so if we don't specify this parameter, it's going to default to valid padding. Since we're using valid padding here, we expect the dimension of our output from each of these convolutional layers to decrease.
Let's check. Here is the summary of this model.
> model_valid.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 20, 20, 16) 64
_________________________________________________________________
conv2d_1 (Conv2D) (None, 18, 18, 32) 4640
_________________________________________________________________
conv2d_2 (Conv2D) (None, 14, 14, 64) 51264
_________________________________________________________________
conv2d_3 (Conv2D) (None, 8, 8, 128) 401536
_________________________________________________________________
flatten_1 (Flatten) (None, 8192) 0
_________________________________________________________________
dense_3 (Dense) (None, 2) 16386
=================================================================
Total params: 473,890
Trainable params: 473,890
Non-trainable params: 0
_________________________________________________________________
We can see the output shape of each layer in the second column. The first two integers specify the dimension of the output in height and width. Starting with our first layer, we see our output size is
the original size of our input, 20 x 20.
Once we get to the output of our first convolutional layer, the dimensions decrease to 18 x 18, and again at the next layer, it decreases to 14 x 14, and finally, at the last
convolutional
layer, it decreases to 8 x 8.
So, we start with 20 x 20 and end up with 8 x 8 when it's all done and over with.
On the contrary, now, we can create a second model.
model_same = Sequential([
Dense(16, input_shape=(20,20,3), activation='relu'),
Conv2D(32, kernel_size=(3,3), activation='relu', padding='same'),
Conv2D(64, kernel_size=(5,5), activation='relu', padding='same'),
Conv2D(128, kernel_size=(7,7), activation='relu', padding='same'),
Flatten(),
Dense(2, activation='softmax')
])
This one is an exact replica of the first, except that we've specified same padding for each of the convolutional layers. Recall from earlier that same padding means we want to pad
the
original input before we convolve it so that the output size is the same size as the input size.
Let's look at the summary of this model.
> model_same.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_6 (Dense) (None, 20, 20, 16) 64
_________________________________________________________________
conv2d_7 (Conv2D) (None, 20, 20, 32) 4640
_________________________________________________________________
conv2d_8 (Conv2D) (None, 20, 20, 64) 51264
_________________________________________________________________
conv2d_9 (Conv2D) (None, 20, 20, 128) 401536
_________________________________________________________________
flatten_3 (Flatten) (None, 51200) 0
_________________________________________________________________
dense_7 (Dense) (None, 2) 102402
=================================================================
Total params: 559,906
Trainable params: 559,906
Non-trainable params: 0
_________________________________________________________________
We can see again that we're starting out with our input size of 20 x 20, and if we look at the output shape for each of the convolutional layers, we see that the layers do indeed
maintain
the original input size now.
This is why we call this type of padding same padding. Same padding keeps the input dimensions the same.
Wrapping up
We should now have an understanding for what zero padding is, what it achieves when we add it to our CNN, and how we can specify padding in our own network using Keras. I'll see ya next time .
quiz
 DEEPLIZARD
Message
DEEPLIZARD
Message
resources
updates
Committed by on